| Basis | Traditional Business | E-business |
| 1. Formation | Difficult | Simple |
| 2. Physical presence | Required | more...
Analogy
Learning Objectives
Classification
Learning Objectives
 Letter-based Classification
We have included questions based on the English alphabet. In this type of question, some groups of letters
are provided and you are required to select that group of letters as your answer in which letters do not
follow the same pattern as that of the other groups of letters. The letters in a group are arranged on the
basis of relative distance between the two letters in the English alphabet. In other words, certain numbers
of letters are skipped between the two successive letters in the given group. It will become more clear by
comprehending the examples given below:
Letter-based Classification
We have included questions based on the English alphabet. In this type of question, some groups of letters
are provided and you are required to select that group of letters as your answer in which letters do not
follow the same pattern as that of the other groups of letters. The letters in a group are arranged on the
basis of relative distance between the two letters in the English alphabet. In other words, certain numbers
of letters are skipped between the two successive letters in the given group. It will become more clear by
comprehending the examples given below:
Coding ? Decoding
Coding - Decoding
Learning Objectives
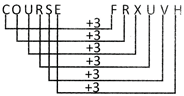 In the given code, each letter is moved three steps forward than the corresponding letter in the word. So R is coded as U, A as D, C as F, E as H.
\[R\,\,\,\,\,\,\Leftrightarrow \,\,\,\,\,\,\,\,U\]
\[A\,\,\,\,\,\,\Leftrightarrow \,\,\,\,\,\,\,\,D\]
\[C\,\,\,\,\,\,\Leftrightarrow \,\,\,\,\,\,\,\,F\]
\[E\,\,\,\,\,\,\Leftrightarrow \,\,\,\,\,\,\,\,H\]
If 'REQUIRED' is coded as 'QERIUDER’, how SINGULAR would be coded?
(a) NISGURAL (b) SINU6RAL
(c) NISRALGU (d) NISUGRAL
(e) None of these
Ans. (d)
Explanation: In the given code/ option (d) is correct.
In the given code, each letter is moved three steps forward than the corresponding letter in the word. So R is coded as U, A as D, C as F, E as H.
\[R\,\,\,\,\,\,\Leftrightarrow \,\,\,\,\,\,\,\,U\]
\[A\,\,\,\,\,\,\Leftrightarrow \,\,\,\,\,\,\,\,D\]
\[C\,\,\,\,\,\,\Leftrightarrow \,\,\,\,\,\,\,\,F\]
\[E\,\,\,\,\,\,\Leftrightarrow \,\,\,\,\,\,\,\,H\]
If 'REQUIRED' is coded as 'QERIUDER’, how SINGULAR would be coded?
(a) NISGURAL (b) SINU6RAL
(c) NISRALGU (d) NISUGRAL
(e) None of these
Ans. (d)
Explanation: In the given code/ option (d) is correct.
 4. In a certain coded BRIGHT is written as JSCSGF. How JOINED would be written in that code?
(a) JPKEFO
(b) JPKCDM
(c) HNIEFO
(d) JPKMDC
(e) None of these
Ans. (b)
4. In a certain coded BRIGHT is written as JSCSGF. How JOINED would be written in that code?
(a) JPKEFO
(b) JPKCDM
(c) HNIEFO
(d) JPKMDC
(e) None of these
Ans. (b)
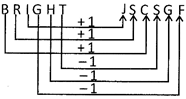 In the given code 1st three letters are moved one step forward and last three letters are moved one step backward than the corresponding letter in the word.
In the given code 1st three letters are moved one step forward and last three letters are moved one step backward than the corresponding letter in the word.
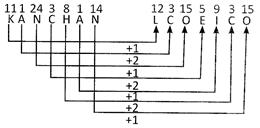
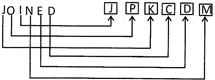 5. In certain code JAYANTI is written as KCZCOVJ. How KANCHAN would be written in that code?
(a) LCOJECO
(b) LCOEIOC
(c) LCOEICO
(d) LCEICOO
(e) None of these
Ans. (c)
Explanation:
5. In certain code JAYANTI is written as KCZCOVJ. How KANCHAN would be written in that code?
(a) LCOJECO
(b) LCOEIOC
(c) LCOEICO
(d) LCEICOO
(e) None of these
Ans. (c)
Explanation:
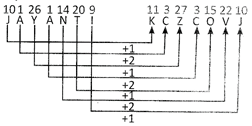 In the given code, continuous letters are added are step and two steps alternatively in forward order.
Similarly,
In the given code, continuous letters are added are step and two steps alternatively in forward order.
Similarly,
 Decreasing order
1. In certain more...
Decreasing order
1. In certain more...
Direction Test
Learning Objectives
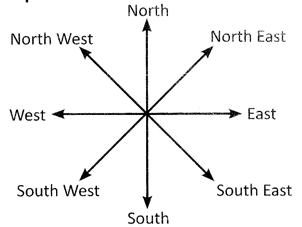 Note: On paper North is always on the top while South is always at the bottom. ·
Example: 1
Note: On paper North is always on the top while South is always at the bottom. ·
Example: 1
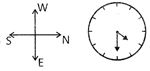 · Example 2
2. Sanjeev walks 10 metres towards the South. Turning to the left, he walks 20 metres and then moves to his right. After moving a distance of 20 metres, he turns to the right and walks 20 metres. Finally, he turns to the right and moves a distance of 10 metres. How far and in which direction is he from the starting point?
(a) 10 metres North (b) 20 metres South
(c) 20 metres North (d) 10 metres South
(e) None of these
Ans. (b)
· Example 2
2. Sanjeev walks 10 metres towards the South. Turning to the left, he walks 20 metres and then moves to his right. After moving a distance of 20 metres, he turns to the right and walks 20 metres. Finally, he turns to the right and moves a distance of 10 metres. How far and in which direction is he from the starting point?
(a) 10 metres North (b) 20 metres South
(c) 20 metres North (d) 10 metres South
(e) None of these
Ans. (b)
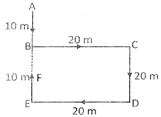 Explanation: The movements of Sanjeev from A to F are as shown in figure.
Clearly, Sanjeev's distance from starting point A
= AF = (AB + BF)
= AB + (BE - EF) = AB + (CD - EF) =
[10 + (20 - 10)] m = (10 + 10) m = 20 m
Also, F lies to the South of A
So, Sanjeev is 20 metres to the south of his starting point. ·
Example 3
I am facing south. I turn right and walk 20m. Then I turn right again and walk 10 m. Then I turn left and walk 10 m and then turning right walk 20 m. Then I turn right again and walk 60 more...
Explanation: The movements of Sanjeev from A to F are as shown in figure.
Clearly, Sanjeev's distance from starting point A
= AF = (AB + BF)
= AB + (BE - EF) = AB + (CD - EF) =
[10 + (20 - 10)] m = (10 + 10) m = 20 m
Also, F lies to the South of A
So, Sanjeev is 20 metres to the south of his starting point. ·
Example 3
I am facing south. I turn right and walk 20m. Then I turn right again and walk 10 m. Then I turn left and walk 10 m and then turning right walk 20 m. Then I turn right again and walk 60 more...
Learning Objectives
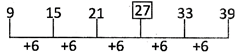 Missing number = 21 + 6 = 27.
2. Which is the number that should come next in the following series?
3, 4, 6, 9, 13, ?
(a) 20
(b) 19
(c) 18
(d) 17
(e) None of these
Ans. (c)
Explanation:
Missing number = 21 + 6 = 27.
2. Which is the number that should come next in the following series?
3, 4, 6, 9, 13, ?
(a) 20
(b) 19
(c) 18
(d) 17
(e) None of these
Ans. (c)
Explanation:
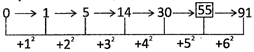
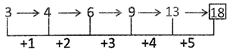 Missing number = 13 + 5 = 18
3. Which number would replace the question mark (?) in the series
0, 1, 5, 14, 30, ?, 91
(a) 65
(b) 55
(c) 45
(d) 35
(e) None of these
Ans. (b)
Explanation:
Missing number = 13 + 5 = 18
3. Which number would replace the question mark (?) in the series
0, 1, 5, 14, 30, ?, 91
(a) 65
(b) 55
(c) 45
(d) 35
(e) None of these
Ans. (b)
Explanation:
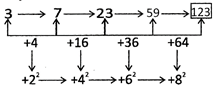
 4. Which is the number that should come next in the following series?
3, 7, 23, 59, ___.
(a) 123 (b) 112
(c) 96 (d) 75
(e) None of these
Ans. (a)
Explanation:
4. Which is the number that should come next in the following series?
3, 7, 23, 59, ___.
(a) 123 (b) 112
(c) 96 (d) 75
(e) None of these
Ans. (a)
Explanation:
 Commonly Asked Questions
Commonly Asked Questions
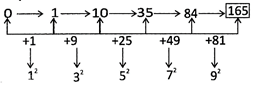
1. Which is the number that should come next in the following series?
0, 1, 10, 35, 84, ___.
(a) 175 (b) 165
(c) 145 (d) 121
(e) None of these
Ans. (b)
Explanation:
Commonly Asked Questions
Commonly Asked Questions
1. Which is the number that should come next in the following series?
0, 1, 10, 35, 84, ___.
(a) 175 (b) 165
(c) 145 (d) 121
(e) None of these
Ans. (b)
Explanation:
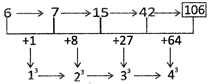
 2. Which is the number that should come next in the following series?
6, 7, 15, 42, ___.
(a) 120 (b) 116
(c) 106 (d) 96
(e) None of these
Ans. (c)
Explanation:
2. Which is the number that should come next in the following series?
6, 7, 15, 42, ___.
(a) 120 (b) 116
(c) 106 (d) 96
(e) None of these
Ans. (c)
Explanation:
 3. Which number would replace the question mark more...
3. Which number would replace the question mark more...
Blood Relation
Learning Objectives
Syllogism
Learning Objectives
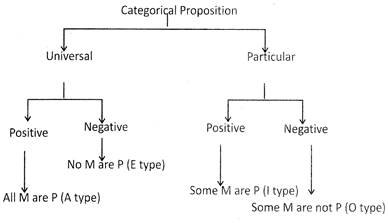 Universal Positive Proposition (a)
A proposition of the form "All S are P" is called a universal positive proposition. A universal positive proposition is denoted by A.
Universal Positive Proposition (a)
A proposition of the form "All S are P" is called a universal positive proposition. A universal positive proposition is denoted by A.
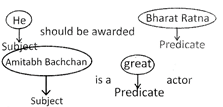 Thus, a positive sentence with a more...
Thus, a positive sentence with a more...
Inserting Number Test
Learning Objectives
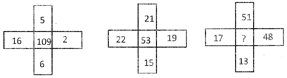 (a) 45 (b) 35
(c) 25 (d) 15
(e) None of these
Ans. (c)
Explanation: The pattern is
\[\to {{(16-6)}^{2}}+{{(5-2)}^{2}}=100+9=109\]
\[\to {{(22-15)}^{2}}+{{(21+19)}^{2}}=49+4=53\]
\[\to {{(17-13)}^{2}}+{{(51-48)}^{2}}=16+9=\]
2.
(a) 45 (b) 35
(c) 25 (d) 15
(e) None of these
Ans. (c)
Explanation: The pattern is
\[\to {{(16-6)}^{2}}+{{(5-2)}^{2}}=100+9=109\]
\[\to {{(22-15)}^{2}}+{{(21+19)}^{2}}=49+4=53\]
\[\to {{(17-13)}^{2}}+{{(51-48)}^{2}}=16+9=\]
2. 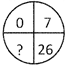 (a) 63 (b) 60
(c) 50 (d) 45
(e) None of these
Ans. (a)
Explanation: Moving clockwise direction, the numbers are
\[{{1}^{3}}-1=0,\,\,{{2}^{3}}-1=7,\,\,{{3}^{3}}-1=26\,\,and\,\,{{4}^{3}}-1=63\]
3.
(a) 63 (b) 60
(c) 50 (d) 45
(e) None of these
Ans. (a)
Explanation: Moving clockwise direction, the numbers are
\[{{1}^{3}}-1=0,\,\,{{2}^{3}}-1=7,\,\,{{3}^{3}}-1=26\,\,and\,\,{{4}^{3}}-1=63\]
3. 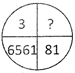 (a) 4 (b) 9
(c) 24 (d) 27
(e) None of these
Ans. (b)
Explanation: Starting from 3 and moving clockwise, the number in each quadrant is the square of that in the previous quadrant. So, the missing number \[={{3}^{2}}=9.\]
4.
(a) 4 (b) 9
(c) 24 (d) 27
(e) None of these
Ans. (b)
Explanation: Starting from 3 and moving clockwise, the number in each quadrant is the square of that in the previous quadrant. So, the missing number \[={{3}^{2}}=9.\]
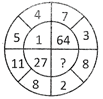
4.  (a) 50 (b) 39
(c) 26 (d) 1
(e) None of these
Ans. (b)
Explanation: The pattern is \[3\times 2-1=5\]
\[\to 5\times 2-2=8\]
\[\to 8\times 2-3=13\]
\[\to 13\times 2-4=22\]
So, \[22\times 2-5=39\]
5.
(a) 50 (b) 39
(c) 26 (d) 1
(e) None of these
Ans. (b)
Explanation: The pattern is \[3\times 2-1=5\]
\[\to 5\times 2-2=8\]
\[\to 8\times 2-3=13\]
\[\to 13\times 2-4=22\]
So, \[22\times 2-5=39\]
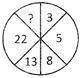
5.  (a) 35 (b) 32
(c) 22 (d) 19
(e) None of these
Ans. (d)
Explanation: Starting from 27 and moving clockwise, the number in alternate segments from the series - 27, 30, 33, 36. The number in remaining segments moving anti clockwise, may from the series - \[,\text{ }21,\text{ }23,\text{ }25,\] or \[21,\text{ }23,\text{ }25\text{ }.\]
So, the missing number is either 19 or 27.
6.
(a) 35 (b) 32
(c) 22 (d) 19
(e) None of these
Ans. (d)
Explanation: Starting from 27 and moving clockwise, the number in alternate segments from the series - 27, 30, 33, 36. The number in remaining segments moving anti clockwise, may from the series - \[,\text{ }21,\text{ }23,\text{ }25,\] or \[21,\text{ }23,\text{ }25\text{ }.\]
So, the missing number is either 19 or 27.
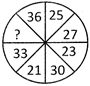
6.  (a) 0 (b) 25
(c) 125 (d) 216
(e) None of these
Ans. (d)
Explanation: The pattern is
\[{{(5-4)}^{3}}=1\]
\[{{(7-3)}^{3}}=64\]
\[{{(11-8)}^{3}}=27\]
So, the missing number \[={{\left( 8-2 \right)}^{3}}=216.\]
7.
(a) 0 (b) 25
(c) 125 (d) 216
(e) None of these
Ans. (d)
Explanation: The pattern is
\[{{(5-4)}^{3}}=1\]
\[{{(7-3)}^{3}}=64\]
\[{{(11-8)}^{3}}=27\]
So, the missing number \[={{\left( 8-2 \right)}^{3}}=216.\]
7. 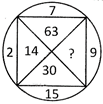 (a) 18
(b) 36
(c) 135
(d) 175
(e) None of these
Ans. (c)
Explanation: The pattern is
\[15\times 2=30\]
\[2\times 7=63\]
So, the missing number is \[9\times 15=135.\]
Commonly Asked Questions
Direction: In each of the following questions a set of figures carrying certain characters, is given. Assuming that the characters in each set follow a similar pattern, find the missing character in each case.
1.
(a) 18
(b) 36
(c) 135
(d) 175
(e) None of these
Ans. (c)
Explanation: The pattern is
\[15\times 2=30\]
\[2\times 7=63\]
So, the missing number is \[9\times 15=135.\]
Commonly Asked Questions
Direction: In each of the following questions a set of figures carrying certain characters, is given. Assuming that the characters in each set follow a similar pattern, find the missing character in each case.
1. 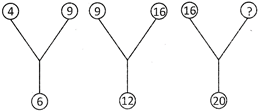 (a) 21 (b) 25
(c) 35 (d) 45
(e) None of these
Ans. (b)
Explanation: We have \[\sqrt{4}\times \sqrt{9}=2\times 3=6\]
\[\sqrt{9}\times \sqrt{16}=3\times 4=12\]
Let the missing number be x. Then
\[\sqrt{16}\times \sqrt{x}=20\]
\[\sqrt{x}=\frac{20}{\sqrt{16}}=\frac{20}{4}=5\]
\[\Rightarrow x={{(5)}^{2}}=25\]
2. more...
(a) 21 (b) 25
(c) 35 (d) 45
(e) None of these
Ans. (b)
Explanation: We have \[\sqrt{4}\times \sqrt{9}=2\times 3=6\]
\[\sqrt{9}\times \sqrt{16}=3\times 4=12\]
Let the missing number be x. Then
\[\sqrt{16}\times \sqrt{x}=20\]
\[\sqrt{x}=\frac{20}{\sqrt{16}}=\frac{20}{4}=5\]
\[\Rightarrow x={{(5)}^{2}}=25\]
2. more...
Logic Venn Diagram Test
Learning Objectives
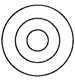 (b) (b) 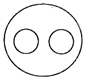 (c)
(c) 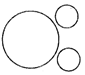 (d) (d) 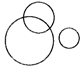 (e)
(e) 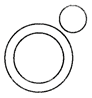 1. Vegetables, Potato Cabbage
Ans. (b)
Explanation:
1. Vegetables, Potato Cabbage
Ans. (b)
Explanation:
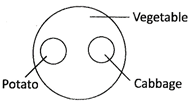 Potato and Cabbage are entirely different, but, both are vegetables.
2. Table, Chair, Furniture
Ans. (b)
Explanation:
Potato and Cabbage are entirely different, but, both are vegetables.
2. Table, Chair, Furniture
Ans. (b)
Explanation:
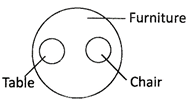 Table and Chair are entirely different, but, both are a part of furniture. 3. Week, Day, Year
Ans. (a)
Explanation:
Table and Chair are entirely different, but, both are a part of furniture. 3. Week, Day, Year
Ans. (a)
Explanation:
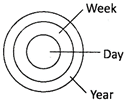 An year consists of weeks, and a week consists of days.
4. Judge, Thief, Criminal
Ans. (e)
Explanation:
An year consists of weeks, and a week consists of days.
4. Judge, Thief, Criminal
Ans. (e)
Explanation:
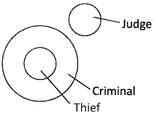 All thieves are criminal But judge is different.
5. Husband, Wife, Family
Ans. (b)
Explanation:
All thieves are criminal But judge is different.
5. Husband, Wife, Family
Ans. (b)
Explanation:
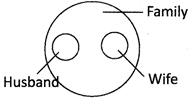 Husband and Wife are entirely different. But both are parts of a family.
6. Square, Rectangle, Polygon
Ans. (a)
Explanation:
Husband and Wife are entirely different. But both are parts of a family.
6. Square, Rectangle, Polygon
Ans. (a)
Explanation:
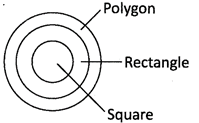 All squares are rectangles. All rectangles are polygons.
7. Bus, Car, Vehicle
Ans. (b)
Explanation:
All squares are rectangles. All rectangles are polygons.
7. Bus, Car, Vehicle
Ans. (b)
Explanation:
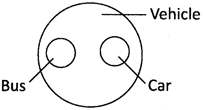 Bus and Car are entirely different. But, both are vehicles.
8. Anxiety, intelligence. Strength
Ans. (c)
Explanation:
Bus and Car are entirely different. But, both are vehicles.
8. Anxiety, intelligence. Strength
Ans. (c)
Explanation:
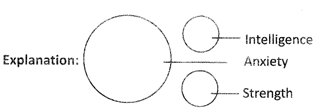 Anxiety/ Intelligence and Strength are entirely different from each other.
9. House, Bedroom, Bathroom
Ans. (b)
Explanation:
Anxiety/ Intelligence and Strength are entirely different from each other.
9. House, Bedroom, Bathroom
Ans. (b)
Explanation:
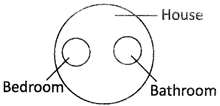 Bedroom and Bathroom are entirely different. But, both are parts of a house.
10. Mustard, Barley, Potato
Ans. (c)
Explanation:
Bedroom and Bathroom are entirely different. But, both are parts of a house.
10. Mustard, Barley, Potato
Ans. (c)
Explanation:
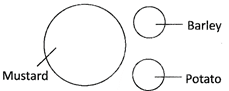 Mustard, Barley and Potato are all separate items/ entirely different from each other. Commonly Asked Questions Directions: In the following questions, three classes are given. Out of the five figures that follow, you are to indicate which figure will best represent the relationship amongst the three classes. (a)
Mustard, Barley and Potato are all separate items/ entirely different from each other. Commonly Asked Questions Directions: In the following questions, three classes are given. Out of the five figures that follow, you are to indicate which figure will best represent the relationship amongst the three classes. (a) 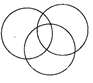 (b) (b)  more... more... Current Affairs CategoriesArchive
Trending Current Affairs



You need to login to perform this action. |

